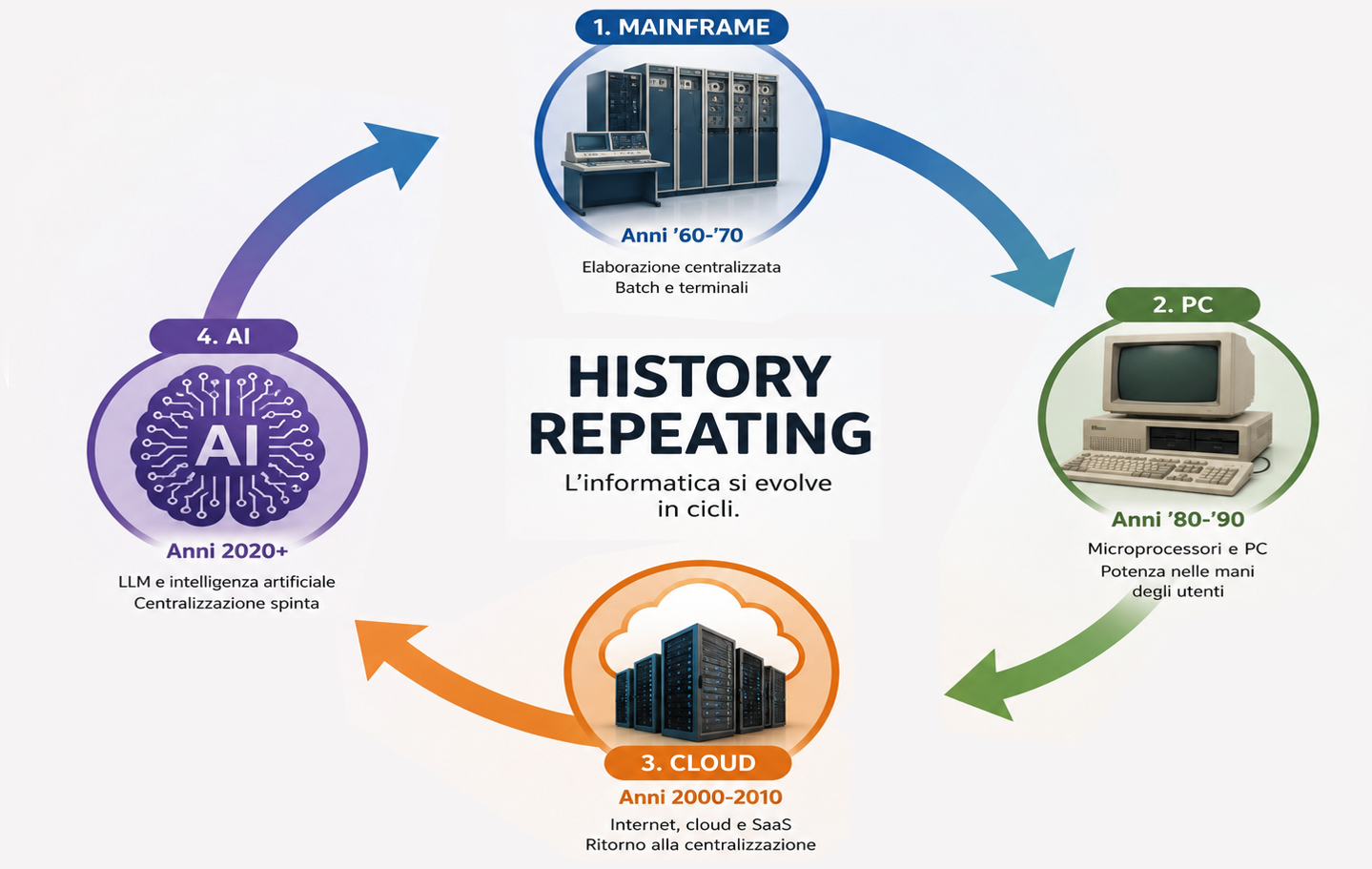
Dai mainframe alle AI locali
Osservando l’evoluzione dell’informatica nell’arco degli ultimi cinquant’anni, ho maturato l’idea che il settore non proceda in linea retta, ma attraverso cicli. Cambiano le tecnologie, cambiano i nomi, cambiano le modalità operative, ma alcune dinamiche di fondo sembrano ripresentarsi continuamente, quasi come se l’intera storia dell’informatica oscillasse fra spinte opposte: centralizzazione e decentralizzazione, controllo locale e servizi remoti, autonomia individuale e concentrazione delle risorse.
Quando iniziai la mia attività professionale, nel lontano 1977, l’informatica era ancora fortemente legata al modello centralizzato. Si viveva nell’epoca dei grandi centri di calcolo, dei sistemi batch e dei terminali collegati a macchine che occupavano intere sale. La potenza di elaborazione era un bene raro e costoso, e proprio per questo doveva essere concentrata. L’utente finale aveva accesso alle risorse attraverso procedure rigidamente organizzate, spesso lontane anni luce dall’idea moderna di interattività.
Negli anni successivi arrivò la trasformazione che avrebbe cambiato completamente il panorama: il microprocessore. La rivoluzione microinformatica non fu soltanto un progresso tecnico, ma anche culturale. La possibilità di avere capacità elaborativa direttamente sulla scrivania modificò radicalmente il rapporto fra uomo e macchina. I personal computer iniziarono progressivamente a sostituire molti dei compiti prima demandati ai grandi sistemi centralizzati. Persino i grandi elaboratori, che nel frattempo si erano evoluti verso il time-sharing, persero progressivamente centralità rispetto a un modello distribuito, dove il controllo ritornava nelle mani dell’utente.
Per qualche tempo sembrò che quella direzione fosse irreversibile. Il PC rappresentava autonomia, indipendenza, possibilità di sperimentazione personale. Anche chi proveniva dall’informatica professionale percepiva chiaramente il cambiamento: non si trattava più soltanto di usare costose risorse condivise, ma di possedere realmente – e controllare – il proprio ambiente operativo.
Poi arrivò Internet.
Con la rete si aprì una nuova fase, inizialmente quasi invisibile, che nel tempo avrebbe riportato il baricentro dell’informatica verso la centralizzazione. Prima il modello client-server, poi i servizi web, infine il cloud e il SaaS1 hanno progressivamente trasformato il personal computer in qualcosa di molto diverso rispetto alla macchina autonoma immaginata negli anni Ottanta. Oggi buona parte del software che utilizziamo quotidianamente non risiede realmente sui nostri sistemi: il browser è diventato il terminale universale di una nuova generazione di centri di calcolo distribuiti su scala globale.
In un certo senso, siamo ritornati a un paradigma sorprendentemente simile a quello originario. Cambiano le tecnologie, naturalmente. I data center moderni non hanno quasi nulla in comune con i centri elaborazione di quarant’anni fa, e i terminali odierni possiedono una potenza immensamente superiore ai vecchi mainframe. Eppure il principio di fondo è tornato molto vicino a quello delle origini: la capacità elaborativa più importante è nuovamente concentrata altrove.
Oggi questa tendenza appare ancora più evidente con l’avvento delle grandi intelligenze artificiali generative e dei LLM. I modelli linguistici di grandi dimensioni rappresentano probabilmente il massimo esempio contemporaneo di centralizzazione computazionale. Addestrare e mantenere operative queste infrastrutture richiede investimenti enormi, capacità energetiche significative e una quantità di risorse hardware che pochi soggetti al mondo possono realmente sostenere.
Ma proprio qui iniziano a emergere dinamiche che ricordano molto da vicino quelle che, decenni fa, portarono alla nascita della microinformatica.
I costi di accesso ai servizi AI stanno crescendo. La dipendenza dai provider esterni diventa sempre più evidente. Molti iniziano (finalmente) a percepire come problematico il fatto che strumenti essenziali del proprio lavoro o della propria attività creativa dipendano integralmente da piattaforme remote, soggette a canoni, limitazioni, cambiamenti unilaterali o semplicemente indisponibilità del servizio.
Nel frattempo, però, la tecnologia continua ad avanzare. I modelli diventano progressivamente più piccoli ed efficienti. Le tecniche di quantizzazione migliorano rapidamente. Le GPU consumer e le nuove NPU integrate nei computer personali iniziano a rendere possibile un’inferenza2 locale che fino a poco tempo fa sembrava impensabile. Sempre più utenti sperimentano modelli eseguiti direttamente sulle proprie workstation, spesso senza necessità di connessioni permanenti al cloud.
Per questo motivo ho la netta sensazione che ci troviamo all’inizio di una nuova oscillazione storica. Certo assisteremo alla scomparsa del cloud o dei grandi provider AI, così come i mainframe non scomparvero realmente con l’arrivo del PC. Piuttosto, penso che vedremo emergere un ecosistema ibrido, nel quale l’addestramento dei grandi modelli resterà fortemente centralizzato, mentre una parte crescente dell’elaborazione quotidiana tornerà verso sistemi locali e personali.
In fondo, l’informatica raramente elimina completamente ciò che esisteva prima. Più spesso ridefinisce i ruoli. Il batch non è mai scomparso. I mainframe esistono ancora. Il time-sharing sopravvive sotto nuove forme nei servizi cloud moderni. Persino il vecchio terminale “stupido” è in qualche modo rinato nel browser web.
E’ probabile che anche il futuro dell’intelligenza artificiale seguirà lo stesso schema. Già oggi molti professionisti del settore, me compreso, utilizzano abitualmente modelli locali, spesso su workstation dotate di GPU o NPU con risorse significative, ottenendo prestazioni che fino a pochi anni fa sarebbero state considerate esclusiva dei grandi provider. Potremmo assistere alla nascita di una nuova “microinformatica dell’AI”, fatta di agenti personali, modelli locali, elaborazione distribuita e maggiore controllo individuale.
L’interesse verso l’AI locale non nasce soltanto dal desiderio di ridurre i costi o recuperare autonomia operativa. C’è anche una crescente attenzione verso aspetti come la privacy, la sovranità dei dati e la resilienza operativa. Eseguire i modelli direttamente sui propri sistemi significa evitare che informazioni sensibili debbano lasciare l’ambiente controllato dell’utente; significa poter continuare a lavorare anche in assenza di connessione o in caso di disservizi dei provider; significa, in definitiva, riappropriarsi del controllo sui propri flussi informativi. È un cambiamento che non riguarda solo la tecnologia, ma il rapporto stesso fra individui, dati e infrastrutture digitali.
E forse i piccoli sistemi AI domestici di domani verranno ricordati, fra qualche decennio, nello stesso modo in cui oggi ricordiamo i primi personal computer degli anni Ottanta: come il momento in cui una tecnologia inizialmente accessibile solo ai grandi centri tornò lentamente nelle mani delle persone.
1) SaaS (Software as a Service) è un modello di distribuzione del software in cui le applicazioni non vengono installate e gestite localmente, ma sono ospitate su server remoti e utilizzate tramite Internet, solitamente via browser. In pratica l’utente non “possiede” il software, ma lo usa come servizio, pagando spesso un abbonamento. Questo permette aggiornamenti continui, accesso da più dispositivi e,apparentemente, minori costi di gestione, ma introduce anche una rilevante dipendenza sia dal fornitore del servizio che dalla connessione di rete.
2) Inferenza è il processo con cui si ricava una conclusione a partire da informazioni già note, senza aggiungere nuovi dati: si collegano elementi esistenti per ottenere qualcosa che non era stato detto esplicitamente. Nel contesto delle intelligenze artificiali indica l’uso di un modello già addestrato per generare una risposta o una previsione a partire da dati in input.